
As artificial intelligence (AI) and machine learning (ML) reshape industries and redefine possibilities, mastering the art of AI and ML model development and evaluation has never been more crucial. Behind every powerful AI or ML model lies strategic decisions, intricate algorithms and critical evaluations. Within the Model and Evaluate phases of the Columbus AI Innovation Lab, we delve into these aspects and how to use diverse metrics to evaluate a machine learning model’s performance, along with its strengths and weaknesses.
To create an artificial intelligence (AI) solution that’s effective at solving your business challenges, you must first define valuable use cases for AI. Then, select AI use cases that would help your business succeed. The third step in making AI work for your business is transforming your data, and after that, it’s time to train and evaluate your AI/machine learning model, which we’ll cover here.
Model evaluation plays a pivotal role in assessing a model’s efficacy and in achieving the defined business goal. A statistical or machine learning model’s performance and efficacy are measured quantitatively using evaluation metrics. These metrics aid in comparing various models or algorithms and offer information on how well the model is working.
Although ML models are becoming more popular, it is essential to understand that ML is not a panacea for all issues. A ML model is a graphical representation of an algorithm that sorts through enormous amounts of data to find trends or make predictions. AI’s data-driven mathematical algorithms are machine learning models. As AI analyzes business use cases, the model evolves based on behaviors.
Only some business challenges require ML techniques to solve them. For example, if you can compute a value using simple arithmetic operations that can be programmed, you do not need machine learning.
Managing the lack or shortage of data in machine learning
The most frequent but resolvable problem with machine learning is a lack of data. Collecting data from your business or obtaining data from open sources is typically not sufficient for generating data for machine learning. Synthetic data is the cheapest and the most convenient data generation type for machine learning. Unlike authentic data collected from real-world events such as customer purchases, consumer feedback or reviews, synthetic data, whether manually generated or created through computer algorithms, enables secure testing of your project by generating data that might not even exist. For example, Google's Waymo uses synthetic data to train its self-driving cars.
Machine learning can be used with non-tabular data but requires some data manipulation. For example, data from various sources like sensors, web crawlers and near-infrared detection instruments can be transformed into a tabular representation by extracting windowed features using common statistical metrics (mean, median, standard deviation, skewness, kurtosis, etc.). The features can then be used with traditional machine learning techniques.
Model training
Writing and running machine learning algorithms to produce an ML model is the central component of the ML workflow. A data science team typically uses the model engineering pipeline, which consists of several procedures, such as model testing, model evaluation and model packaging, to create the final model.
You can streamline these activities in several ways. For example, you can automate the machine learning model training process by building a pipeline, which makes it simpler to scale the solution to larger datasets and maintain and update the model over time.
It is important to understand how crucial and interconnected the stages of model training, evaluation and testing are in the machine-learning workflow. Model creation is followed by model training, assessment of the model’s performance on a different dataset and testing of the model on fresh or previously unexplored data. Since this process is iterative, it may be necessary to repeat model training several times before the model’s performance on the testing data is acceptable.
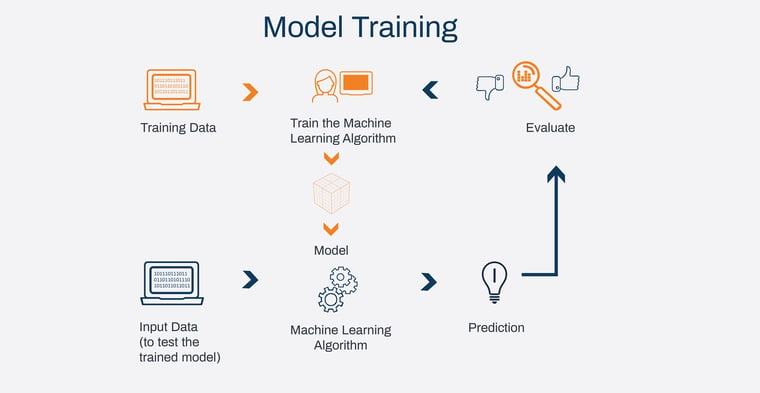
The model training phase includes these steps/actions:
- Depending on the data you need and your learning objectives, choose the appropriate algorithm.
- Choose the architecture, model variant or other parameters that will produce the best results.
- Set up, fine-tune and create the model parameter values that a machine learning algorithm eventually learns. The term “hyperparameter” refers to this regulatory mechanism. In order to get the best results, the model version is chosen with the aid of this hyperparameter adjustment. Examples include the number of layers, activation function and learning rate in neural networks, which are all controlled via fine-tuning.
- To demonstrate which hyperparameters and models are most effective for your use case, benchmark them.
- Determine whether the model has the necessary level of explainability.
- Consider using an ensemble technique, which involves running multiple models concurrently, if applicable, or a more advanced technique if required by the business challenges or objective.
The effectiveness and accuracy of machine learning models are also influenced by feature engineering, which is the method of converting unprocessed data into features appropriate for machine learning models. To create more precise and effective machine learning models, the most pertinent features from the given data are chosen, extracted and transformed. Users must provide the correct data that the algorithms can understand for machine algorithms to function successfully. This input data is changed by feature engineering into a single aggregated form that is best for machine learning.
For instance, in a model predicting the price of a certain house, the outcome variable is the data showing the actual price. The predictor variables are the data showing such things as the size of the house, number of bedrooms and location — features thought to determine the value of the home.
Feature engineering use cases:
- Calculating a person’s age from the individual’s birth date and the current date
- Obtaining the average and median retweet count of particular tweets
- Acquiring word and phrase counts from news articles
- Extracting pixel information from images
- Tabulating how frequently teachers enter various grades
The two methods used for ML model training are:
- Offline learning (also known as batch learning or static learning): The model is taught using pre-existing data. The ML model stays the same after deployment to the operational environment until it is re-trained. As additional data becomes available, the model will become stale and experience model deterioration until it gets retrained. This situation requires close monitoring.
For instance, retail businesses can utilize offline learning for targeted marketing by grouping customers based on buying habits or demographic similarities, and by projecting what one person may want from someone else’s purchases. While some suggested purchase pairings are obvious, offline machine learning can get eerily accurate by finding hidden relationships in data and predicting what you want before you know you want it. - Online learning is a machine learning technique that consumes real-time data samples one observation at a time. With more useful batch algorithms, it processes one sample of data at a time, making it substantially more efficient in terms of time and space.
For example, to evaluate the quality and freshness of food goods, machine learning algorithms can examine a variety of quality indicators, including color, texture and chemical composition. The algorithm can detect and recognize symptoms of deterioration or spoilage by training models on labeled data that indicate varying levels of quality. Using computer vision techniques, real-time monitoring can also be used to find visual signs of spoiling such as mold growth or color changes.
Finding the best settings for hyperparameters is a crucial part of training a model and tuning them can improve model performance. Hyperparameters can significantly affect a machine-learning model’s performance. Here are a few typical training approaches.
- Grid search: Training the model with all conceivable combinations of hyperparameters while specifying a range of values for each one.
- Random search: Using a set of arbitrarily chosen hyperparameter values that fall within a predetermined range.
- Bayesian optimization: This method employs a probabilistic model to forecast how various hyperparameter values will perform and to pick the most promising ones for training.
- Genetic algorithms: To discover the ideal collection of hyperparameters, genetic algorithms evolve a population of potential hyperparameters over several generations.
- Manual tuning: Testing various hyperparameter values and evaluating the model’s performance.
Machine learning can be applied to promote products and services, identify cybersecurity breaches, enable self-driving cars and more to save costs, manage risks and enhance overall quality of life. Machine learning is becoming more commonplace every day and will soon be incorporated into many aspects of daily life due to increased availability of data and computing capacity.
Model evaluation
Model evaluation measures how well a trained machine learning model works to make sure it meets the original business objectives. The goal of model evaluation is to assess a model’s ability to predict outcomes correctly and to pinpoint areas for improvement. To assess a model, a variety of methods can be applied, such as:
- Holdout technique: Data is divided into training and test sets. The model is developed on the training set, and the test set is used to assess the model’s success.
- Bootstrapping: In this method, the model undergoes training using a series of newly generated datasets. These datasets are crafted by resampling the original dataset, allowing the same data point to appear multiple times within a resampled dataset. By employing this method of replacement, the model's performance is evaluated based on the insights gathered from these resampled datasets.
- Cross-validation: In this method, the data is divided into different subgroups, each of which is used as a test set while the other subsets are used for training. This technique aids in lowering the danger of over-fitting which can lead to poor predictive performance.
- Metrics: Depending on the kind of issue being solved, different metrics can be used to assess how well a machine learning model is performing. Accuracy, precision, recall, F1 score, AUC-ROC and mean squared error are a few typical measures.
- Visual inspection: In some circumstances, the output of the model can be visually inspected to assess the success of the model. For instance, in image classification, the model’s success can be evaluated by comparing its predictions to the labels applied.
It is critical to remember that the evaluation procedure should be customized to the unique aspects of the business objective and the dataset. Different evaluation metrics might be more suitable across various models. To assess a ML model and make sure that its performance is understood, it is typical to use a combination of methods.
Model testing
Model testing in machine learning is the process of assessing how well a trained model performs on a collection of data that it has never seen before. Model testing is done to determine how well a model generalizes to new, unforeseen data and to predict how well it will work in practice.
To prevent bias, the testing set should not be used in the training process and should be an accurate representation of the real-world data that the model will meet. To provide a statistically significant evaluation of the model’s performance, the testing set must be big enough. Decisions about the model’s suitability for deployment in the actual world are then made based on the outcomes of the model testing stage.
Model packaging
Model packaging is the practice of combining a trained machine learning model with its related pre- and post-processing steps, configuration files and other essential resources into a unique package that can be readily distributed, deployed and used by others. The trained model can be shared and used in various contexts, such as cloud-based or on-premises systems, thanks to model packaging in the machine learning workflow. Depending on the unique requirements of the use case, a model can be packaged using a variety of techniques.
In this blog, we touched upon model training, evaluation and testing. The features of ML testing include the need to verify the quality of the data as well as the model and the need to iteratively tune the hyperparameters to achieve the best results. You can be certain of its performance if you follow all the steps outlined.
The stages of Deploy and Support in the Columbus AI Innovation Lab will be covered in the last blog in our AI blog series, "How to deploy and support trained AI and ML models."
The Columbus AI Innovation Lab: Make artificial intelligence work for your business
-1.png?width=1537&height=705&name=MicrosoftTeams-image%20(35)-1.png)